Utilizing Machine Studying to Automate Kubernetes Optimization

[ad_1]

Brian Likosar
Brian is an open supply geek with a ardour for working on the intersection of individuals and expertise. All through his profession, he is been concerned in open supply, whether or not that was with Linux, Ansible and OpenShift/Kubernetes whereas at Pink Hat, Apache Kafka whereas at Confluent, or Apache Flink whereas at AWS. Presently a senior options architect at StormForge, he’s based mostly within the Chicago space and enjoys horror, sports activities, dwell music and theme parks.
Be aware: That is the third of a five-part collection overlaying Kubernetes useful resource administration and optimization. On this article, we clarify how machine studying can be utilized to handle Kubernetes assets effectively. Earlier articles defined Kubernetes useful resource sorts and requests and limits.
As Kubernetes has grow to be the de-facto customary for software container orchestration, it has additionally raised important questions on optimization methods and finest practices. One of many causes organizations undertake Kubernetes is to enhance effectivity, even whereas scaling up and all the way down to accommodate altering workloads. However the identical fine-grained management that makes Kubernetes so versatile additionally makes it difficult to successfully tune and optimize.
On this article, we’ll clarify how machine studying can be utilized to automate tuning of those assets and guarantee environment friendly scaling for variable workloads.
The Complexities of Optimization
Optimizing functions for Kubernetes is essentially a matter of guaranteeing that the code makes use of its underlying assets — specifically CPU and reminiscence — as effectively as doable. Which means guaranteeing efficiency that meets or exceeds service-level aims on the lowest doable value and with minimal effort.
When making a cluster, we are able to configure using two major assets — reminiscence and CPU — on the container degree. Particularly, we are able to set limits as to how a lot of those assets our software can use and request. We will consider these useful resource settings as our enter variables, and the output when it comes to efficiency, reliability and useful resource utilization (or value) of working our software. Because the variety of containers will increase, the variety of variables additionally will increase, and with that, the general complexity of cluster administration and system optimization will increase exponentially.

We will consider Kubernetes configuration as an equation with useful resource settings as our variables and value, efficiency and reliability as our outcomes.
To additional complicate issues, completely different useful resource parameters are interdependent. Altering one parameter could have sudden results on cluster efficiency and effectivity. Which means that manually figuring out the exact configurations for optimum efficiency is an unimaginable process, except you will have limitless time and Kubernetes specialists.
If we don’t set customized values for assets throughout the container deployment, Kubernetes mechanically assigns these values. The problem right here is that Kubernetes is sort of beneficiant with its assets to stop two conditions: service failure on account of an out-of-memory (OOM) error and unreasonably sluggish efficiency on account of CPU throttling. Nonetheless, utilizing the default configurations to create a cloud-based cluster will end in unreasonably excessive cloud prices with out guaranteeing ample efficiency.
This all turns into much more advanced after we search to handle a number of parameters for a number of clusters. For optimizing an surroundings’s value of metrics, a machine studying system could be an integral addition.
Machine Studying Optimization Approaches
There are two basic approaches to machine learning-based optimization, every of which offers worth another way. First, experimentation-based optimization could be performed in a non-prod surroundings utilizing quite a lot of situations to emulate doable manufacturing situations. Second, observation-based optimization could be carried out both in prod or non-prod by observing precise system habits. These two approaches are described subsequent.
Experimentation-Based mostly Optimization
Optimizing via experimentation is a strong, science-based method as a result of we are able to attempt any doable state of affairs, measure the outcomes, alter our variables and take a look at once more. Since experimentation takes place in a non-prod surroundings, we’re solely restricted by the situations we are able to think about and the effort and time wanted to carry out these experiments. If experimentation is finished manually, the effort and time wanted could be overwhelming. That’s the place machine studying and automation are available.
Let’s discover how experimentation-based optimization works in observe.
Step 1: Establish the Variables
To arrange an experiment, we should first establish which variables (additionally known as parameters) could be tuned. These are sometimes CPU and reminiscence requests and limits, replicas and application-specific parameters reminiscent of JVM heap measurement and rubbish assortment settings.
Some ML optimization options can scan your cluster to mechanically establish configurable parameters. This scanning course of additionally captures the cluster’s present, or baseline, values as a place to begin for our experiment.
Step 2: Set Optimization Objectives
Subsequent, you should specify your targets. In different phrases, which metrics are you making an attempt to attenuate or maximize? Normally, the objective will include a number of metrics representing trade-offs, reminiscent of efficiency versus value. For instance, it’s possible you’ll wish to maximize throughput whereas minimizing useful resource prices.
Some optimization options will can help you apply a weighting to every optimization objective, as efficiency could also be extra necessary than value in some conditions and vice versa. Moreover, it’s possible you’ll wish to specify boundaries for every objective. For example, you won’t wish to even contemplate any situations that end in efficiency beneath a selected threshold. Offering these guardrails will assist to enhance the velocity and effectivity of the experimentation course of.
Listed here are some issues for choosing the best metrics to your optimization targets:
- If a containerized software is transaction-based, reduce the response time and the error charge. On this scenario, most velocity is the best and useful resource use is of much less concern.
- If the appliance is just meant for computations, reduce the error charge. We wish to optimize for efficiency effectivity.
- If the appliance processes information, velocity is probably going secondary. Optimize for value.
After all, these are just some examples. Figuring out the correct metrics to prioritize requires communication between builders and people answerable for enterprise operations. Decide the group’s major targets. Then study how the expertise can obtain these targets and what it requires to take action. Lastly, set up a plan that emphasizes the metrics that finest accommodate the stability of value and performance.
Step 3: Set up Optimization Situations
With an experimentation-based method, we have to set up the situations to optimize for and construct these situations right into a load take a look at. This is perhaps a variety of anticipated consumer visitors or a particular state of affairs like a retail holiday-based spike in visitors. This efficiency take a look at will probably be used throughout the experimentation course of to simulate manufacturing load.
Step 4: Run the Experiment
As soon as we’ve arrange our experiment with optimization targets and tunable parameters, we are able to kick off the experiment. An experiment consists of a number of trials, together with your optimization answer iterating via the next steps for every trial:
- The experiment controller runs the containerized software in your cluster utilizing the baseline parameters for the primary trial.
- The controller then runs the efficiency take a look at created beforehand to use load to the system for our optimization state of affairs.
- The controller captures the metrics equivalent to our targets, for instance, period and useful resource value.
- The machine studying algorithm analyzes the outcomes after which calculates a brand new set of parameters for the subsequent trial.
- This course of is then repeated for nonetheless many trials have been specified when configuring your experiment. Typical experiments vary from 20 to 200 trials, with extra parameters requiring extra trials to get a definitive outcome.
The machine studying engine makes use of the outcomes of every trial to construct a mannequin representing the multidimensional parameter house. On this house, it could actually study the parameters in relation to at least one one other. With every iteration, the ML engine strikes nearer to figuring out the configurations that optimize the objective metrics.
Step 5: Analyze Outcomes
Whereas machine studying mechanically recommends the configuration that can outcome within the optimum outcomes, further evaluation could be performed as soon as the experiment is full. For instance, you may visualize the trade-offs between two completely different targets, see which parameters have a major influence on outcomes and which matter much less.
Outcomes are sometimes shocking and may result in key architectural enhancements, for instance, figuring out {that a} bigger variety of smaller replicas is extra environment friendly than a smaller variety of “heavier” replicas.
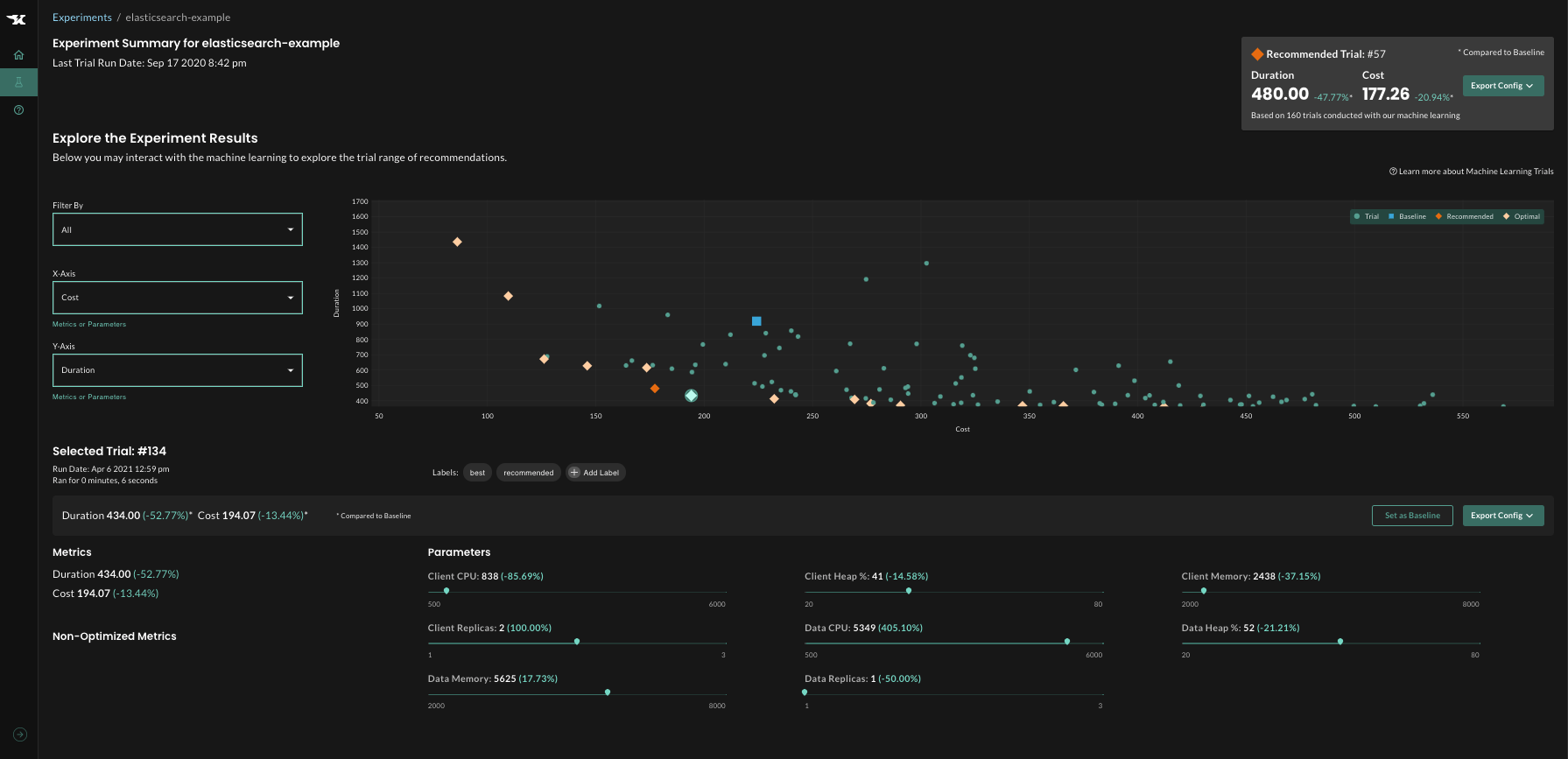
Experiment outcomes could be visualized and analyzed to totally perceive system habits.
Remark-Based mostly Optimization
Whereas experimentation-based optimization is highly effective for analyzing a variety of situations, it’s unimaginable to anticipate each doable scenario. Moreover, extremely variable consumer visitors signifies that an optimum configuration at one cut-off date is probably not optimum as issues change. Kubernetes autoscalers will help, however they’re based mostly on historic utilization and fail to take software efficiency into consideration.
That is the place observation-based optimization will help. Let’s see the way it works.
Step 1: Configure the Software
Relying on what optimization answer you’re utilizing, configuring an software for observation-based optimization could include the next steps:
- Specify the namespace and, optionally, a label selector, to establish which assets to tune.
- Specify guardrails (min. and max.) for the CPU and reminiscence parameters to be tuned.
- Specify how often the system ought to suggest up to date parameter settings.
- Specify whether or not to deploy suggestions mechanically or with approval.
Step 2: Machine Studying Evaluation
As soon as configured, the machine studying engine begins analyzing observability information collected from Prometheus, Datadog or different observability instruments to know precise useful resource utilization and software efficiency tendencies. The system then begins making suggestions on the interval specified throughout configuration.
Step 3: Deploy Suggestions
In case you specified automated implementation of suggestions throughout configuration, the optimization answer will mechanically patch deployments with really helpful configurations as they’re really helpful. In case you chosen guide deployment, you may view the advice, together with container-level particulars, earlier than deciding to approve or not.
Greatest Practices
As you’ll have famous, observation-based optimization is less complicated than experimentation-based approaches. It offers worth quicker with much less effort, however alternatively, experimentation- based mostly optimization is extra highly effective and may present deep software insights that aren’t doable utilizing an observation-based method.
Which method to make use of shouldn’t be an both/or choice; each approaches have their place and may work collectively to shut the hole between prod and non-prod. Listed here are some tips to contemplate:
-
- As a result of observation-based optimization is straightforward to implement and enhancements could be seen rapidly, it needs to be deployed broadly throughout your surroundings.
- For extra advanced or essential functions that might profit from a deeper degree of study, use experimentation-based optimization to complement observation-based.
- Remark-based optimization can be used to establish situations that warrant the deeper evaluation offered by experimentation-based optimization.
- Then use the observation-based method to repeatedly validate and refine the experimentation-based implementation in a virtuous cycle of optimization in your manufacturing surroundings.

Utilizing each experimentation-based and observation-based approaches creates a virtuous cycle of systematic, steady optimization.
Conclusion
Optimizing our Kubernetes surroundings to maximise effectivity (efficiency versus value), scale intelligently and obtain our enterprise targets requires:
- A super configuration of our software and environmental parameters previous to deployment.
- Steady monitoring and adjustment post-deployment.
For small environments, this process is arduous. For a corporation working apps on Kubernetes at scale, it’s possible already past the scope of guide labor.
Happily, machine studying can bridge the automation hole and supply highly effective insights for optimizing a Kubernetes surroundings at each degree.
StormForge offers an answer that makes use of machine studying to optimize based mostly on each statement (utilizing observability information) and experimentation (utilizing performance-testing information).
To attempt StormForge in your surroundings, you may request a free trial right here and expertise how full optimization doesn’t should be an entire headache.
Keep tuned for future articles on this collection the place we’ll clarify find out how to sort out particular challenges concerned in optimizing Java apps and databases working in containers.

[ad_2]
Source_link





