Optimizing knowledge ingestion infrastructure to assist extra AI fashions

[ad_1]
Lots of Meta’s merchandise, resembling search, advertisements rating and Market, make the most of AI fashions to repeatedly enhance consumer experiences. Because the efficiency of {hardware} we use to assist coaching infrastructure will increase, we have to scale our knowledge ingestion infrastructure accordingly to deal with workloads extra effectively. GPUs, that are used for coaching infrastructure, are likely to double in efficiency each two years, whereas the efficiency of CPUs, used for knowledge studying computation, will increase at a a lot slower tempo in the identical timeframe.
To facilitate the extent of knowledge ingestion required to assist the coaching fashions supporting our merchandise, we’ve needed to construct a brand new knowledge ingestion infrastructure in addition to new last-mile transformation pipelines. By optimizing areas of our knowledge ingestion infrastructure, we improved our energy funds requirement by 35-45%, permitting us to assist a rising variety of AI fashions in our energy constrained knowledge facilities.
Meta’s rising AI infrastructure
As our product teams proceed to rely closely on AI fashions to enhance product expertise, the AI infrastructure necessities are rising alongside the next dimensions:
- Variety of fashions being skilled
- Quantity of knowledge and options that fashions practice on
- Mannequin measurement and complexity
- Mannequin coaching throughput
Within the determine beneath, we observe that over the past two years we’ve got grown:
- 1.75-2x within the quantity of knowledge we practice on
- 3-4x in knowledge ingestion throughput

Fig. 1: Normalized dataset measurement development and knowledge ingestion bandwidth development noticed in manufacturing.
Our knowledge facilities should be provisioned to serve infrastructure that trains 1000’s of fashions, every consuming petabyte scale datasets. We should allow our engineers to have most flexibility when experimenting with new options and coaching mannequin architectures. Within the sections beneath, we share our expertise constructing knowledge ingestion and last-mile knowledge preprocessing pipelines which might be answerable for feeding knowledge into AI coaching fashions.
Information ingestion pipeline overview
We have now exabytes of coaching knowledge powering our fashions, and the quantity of coaching knowledge is rising quickly. We have now all kinds of fashions that practice on terabyte- to petabyte-scale knowledge, however we do not need the storage capability at that scale to coach the info regionally on the coaching {hardware}. We retailer and serve coaching knowledge from Tectonic, Meta’s exabyte-scale distributed file system that serves as a disaggregated storage infrastructure for our AI coaching fashions. Our AI coaching datasets are modeled as Hive Tables and encoded utilizing a hybrid columnar format referred to as DWRF, primarily based on the Apache ORC format.
The method of choosing uncooked knowledge and remodeling it into options that may be consumed by machine studying (ML) coaching fashions is named function engineering. That is on the core of ML coaching, and our ML engineers should experiment with new options each day. We mannequin options as maps in coaching tables. This offers Meta’s engineers the pliability so as to add and take away options simply with out repeatedly sustaining the desk schema.
We have now constructed a disaggregated Information PreProcessing tier (DPP) that serves because the reader tier for knowledge ingestion and last-mile knowledge transformations for AI coaching.
That is answerable for:
– Fetching knowledge from Tectonic clusters
– Decrypting and decoding knowledge
– Extracting the options to be consumed by the mannequin
– Changing the info to tensor codecs
– Performing last-mile transformations earlier than precise coaching
For content material understanding fashions, examples of last-mile transformations may imply randomized picture clips or crops to detect objectionable photos, for instance. With suggestion fashions, last-mile transformations sometimes set off operations like function normalization, bucketization, truncation, type by rating, and even operations that mix a number of options to type new options, like ngram, or categorical function intersections and unions.
DPP permits us to scale knowledge ingestion and coaching {hardware} independently, enabling us to coach 1000’s of very various fashions with completely different ingestion and coaching traits. DPP gives an easy-to-use, PyTorch-style API to effectively ingest knowledge into coaching. It permits lessons of recent options by leveraging its disaggregated compute tier to assist function transformations (these operations are sometimes computationally intensive). DPP executes in a knowledge parallel trend, with every compute node (DPP employee) studying, batching, and preprocessing a subset of coaching knowledge rows. A light-weight DPP consumer module invoked within the coach course of fetches knowledge from DPP employee nodes and transfers the info to coaching. DPP will also be invoked as a library on coaching nodes, in what we name the on-box mode, for fashions that do not need excessive throughput calls for. Nevertheless, in apply, lots of our suggestion jobs use tens to tons of of disaggregated nodes to make sure that we are able to meet the info ingestion demand of trainers . A number of of our complicated coaching jobs learn huge volumes of knowledge and might take a number of days to coach. To keep away from wasted compute attributable to failures, DPP has built-in assist to checkpoint knowledge cursors and resume jobs from checkpoints. Failed reader nodes are changed transparently, with out job interruption. DPP can even dynamically scale compute assets allotted for studying to make sure we are able to meet the info throughput calls for from the trainers.
Our coaching infrastructure should serve all kinds of fashions skilled on distributed CPU and GPU {hardware} deployments.
The determine beneath reveals our knowledge ingestion structure:
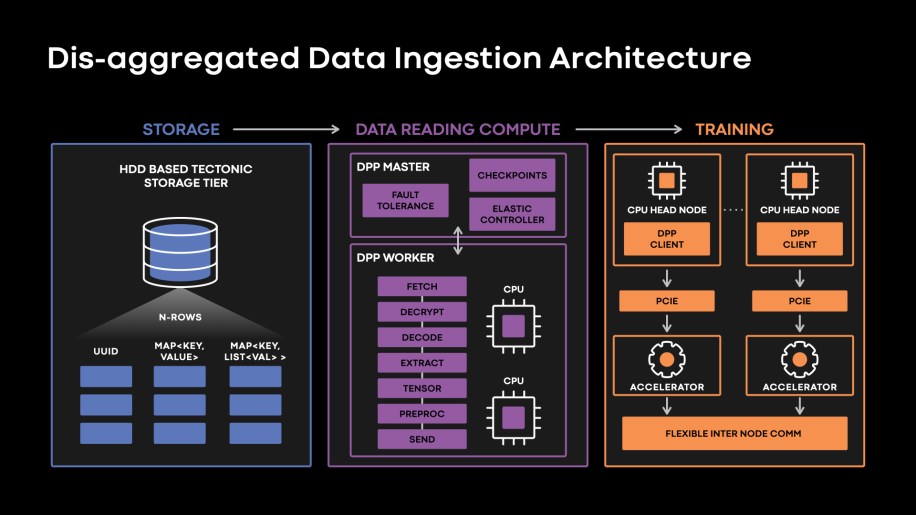
Fig. 2: Final-mile knowledge ingestion infrastructure at Meta.
Information ingestion traits and optimizations
Tendencies in {hardware} evolution and knowledge heart energy constraints
As talked about above, we’ve got a mismatch within the fee of development for our coaching and ingestion {hardware}. Our disaggregated structure enabled us to scale knowledge ingestion for coaching wants. Nevertheless, many suggestion fashions are ingestion-bound (Fig. 3). With a hard and fast energy funds in our knowledge facilities, knowledge ingestion necessities restrict the coaching accelerators we are able to deploy.
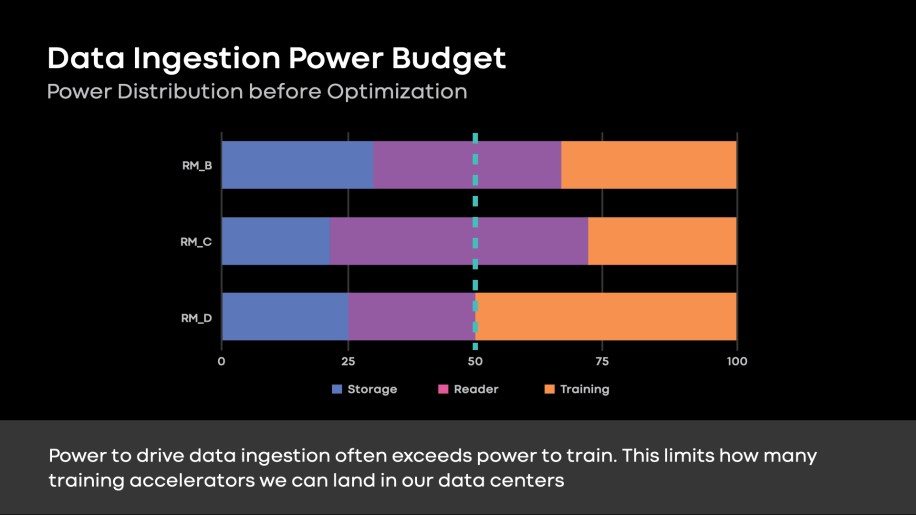
Fig. 3: Storage, reader compute, and coaching energy distribution throughout three suggestion fashions. The sum of energy allocation for storage and reader tiers is dominant for a lot of rating fashions. This limits the coaching accelerators we are able to land in our knowledge facilities, the place we’ve got mounted energy funds constraints.
Information studying tier characterizations and optimizations
We have now profiled a number of manufacturing suggestion fashions, and we’ve summarized the teachings discovered round environment friendly knowledge studying:
Optimizing algorithmic effectivity in readers:
Coaching datasets are sometimes shared throughout a number of jobs, and a single coaching job typically reads solely a subset of the accessible options. This might imply studying as little as 20-37 % of the saved bytes in lots of our distinguished rating fashions.
The unique map column structure didn’t present environment friendly methods to learn a subset of options from the accessible options (see Fig. 4). The information structure of the options within the authentic map meant we needed to fetch, decrypt, and decode your complete map object to extract the options wanted by the mannequin.
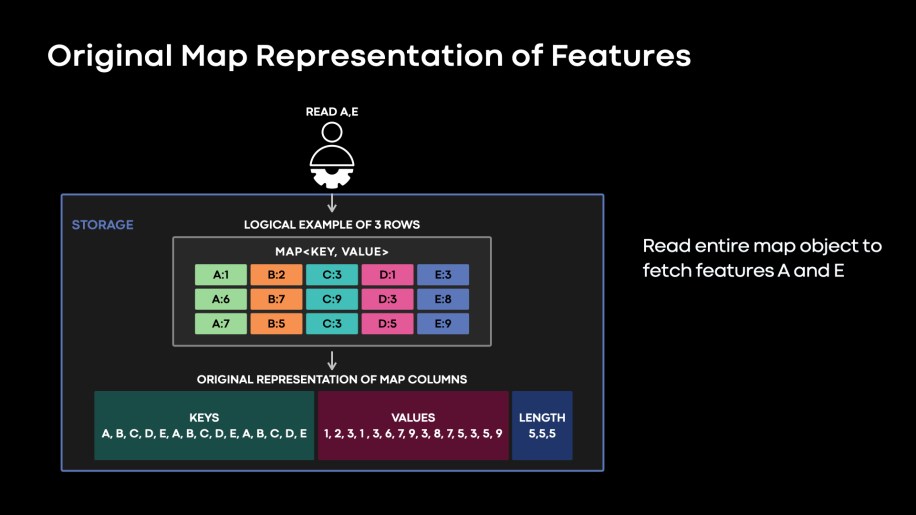
Fig. 4: Unique knowledge structure of the function maps. We have to fetch, decode, and decrypt total Keys, Values, and Lengths columns to extract desired options of A and E.
We applied a brand new storage format referred to as function flattening, which represents every function as a stream on a disk, as if we had n columns as an alternative of a map of n options. This columnar function illustration permits studying subsets of options extra effectively. We name this studying performance as “function projection.”
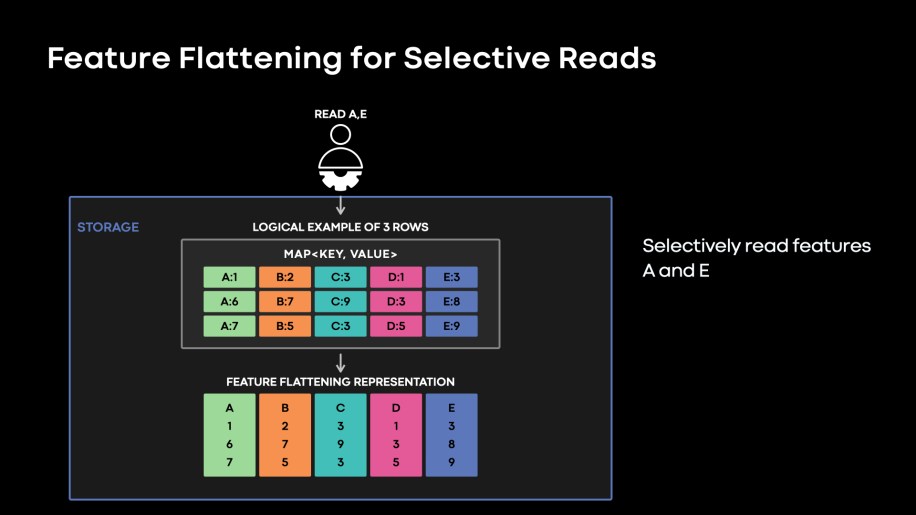
Fig. 5: Characteristic flattening shops particular person options in contiguous streams. This format is extra environment friendly when the purpose is to selectively learn a subset of options.
Since most of our manufacturing workloads had been selective when it comes to options consumed by fashions in contrast with options saved in storage, function projection yielded excessive knowledge studying effectivity wins, to the tune of 2-2.3x. The normalized throughput good points metric proven within the determine beneath signifies the enhancements within the rows/s metric as executed b by every DPP reader.

Fig. 6: Normalized throughput good points from function flattening rollouts in three pattern rating fashions in our manufacturing fleet. Fashions that selectively learn a smaller subset of options within the storage tier (which is typical in our AI coaching manufacturing surroundings) profit from function flattening illustration of knowledge.
Optimizing reminiscence consumption for the info studying tier: The DPP readers present batches of knowledge for coaching, or, numerous enter rows to be consumed in a single coaching iteration. As coaching infrastructure onboarded extra highly effective accelerators, we noticed the development of accelerating batch -sizes to extend the coaching throughput of rows/s on the beefier coaching nodes. We discovered a number of use circumstances the place DPP staff that executed on less complicated CPU nodes turned memory-bound to assist bigger batch sizes. We noticed that almost all customers mitigated this by launching readers with fewer threads to keep away from out-of-memory (OOM) errors. Lowering reader node threads resulted in decreased per-node effectivity, or decreased rows/s as executed by every reader node. To assist massive batches, we proposed DPP client-side rebatching, the place we nonetheless learn smaller batches with {hardware} concurrency on our reader tier nodes. Nevertheless, our consumer on the beefier coaching node is answerable for appending batches to assist massive batch exploration.
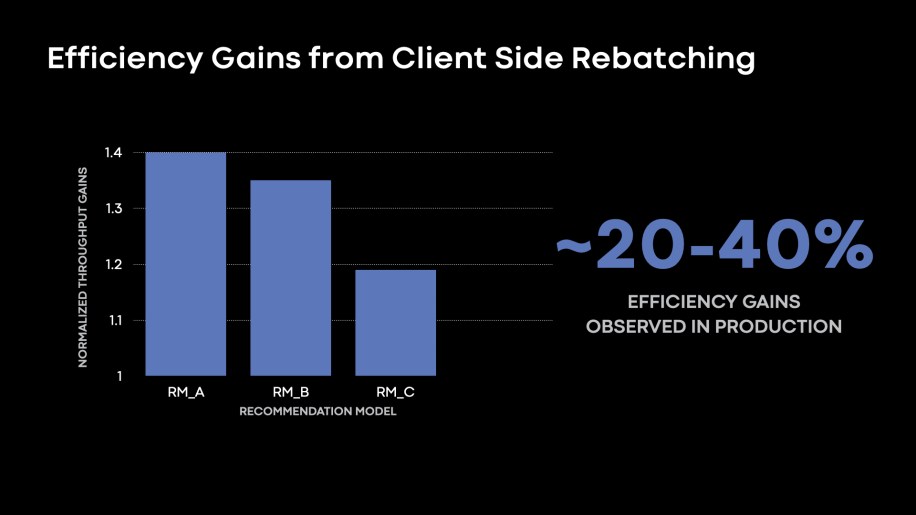
Fig. 7: Round 20-40 % enhancements within the rows/s throughput as executed by every reader node by enabling DPP Shopper aspect rebatching to assist massive batch explorations.
Optimizing reminiscence bandwidth for the info studying tier
We anticipate most of our DPP nodes to be reminiscence bandwidth-bound as we improve our knowledge facilities with newer CPU variations with extra cores (and with no proportional improve of the accessible reminiscence bandwidth). Lots of our knowledge studying workloads in manufacturing are reminiscence bandwidth-bound. We even have recognized scope to enhance our reminiscence bandwidth utilization in preprocessing/transformation operators we executed on the readers. On this part, we’ll talk about the mission of FlatMaps, which yielded enhancements when it comes to reminiscence bandwidth utilization on the DPP readers.
As defined within the part above, with function flattening we modified the bodily structure of our options within the storage tier. Nevertheless, attributable to legacy causes of studying unflattened tables, we recognized that our in-memory illustration of a batch within the DPP reader employee was out of date, triggering pointless format transformations. That is illustrated in Fig. 8, beneath.
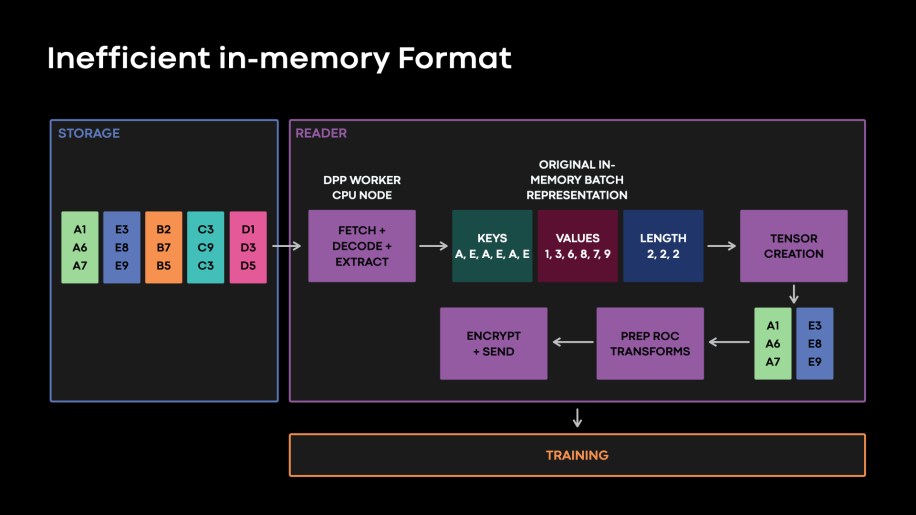
Fig. 8: Our authentic in-memory batch knowledge illustration manifested the unique map structure of options proven in Fig. 4. Studying flattened options from storage, translating this knowledge to the legacy in reminiscence batch illustration after which changing the info to tensors triggered pointless knowledge format transformations.
By figuring out a column main in-memory format to learn flattened tables, we averted pointless knowledge structure transformations as illustrated in Fig. 9, beneath.
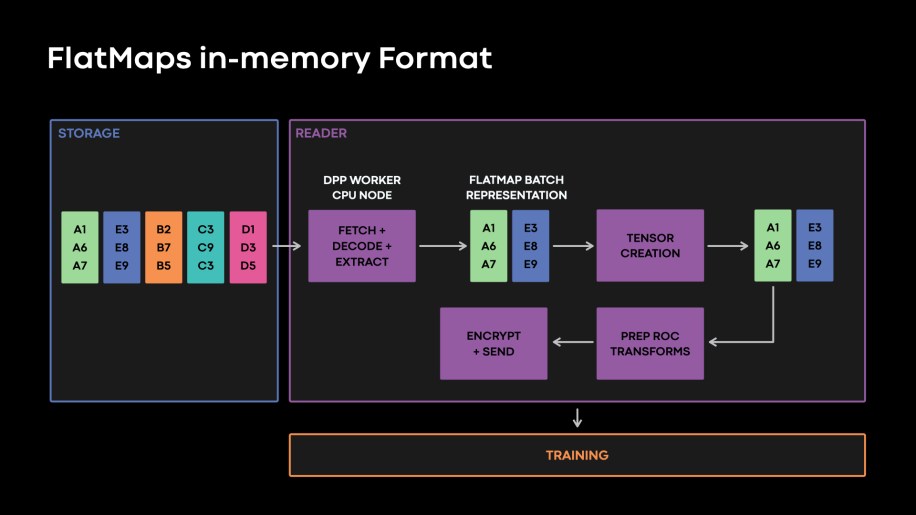
Fig. 9: Illustration of knowledge format and Flatmap in-memory illustration in readers. This in-memory format eliminates pointless knowledge structure transformations from options in our storage tier to tensors that coaching should eat.
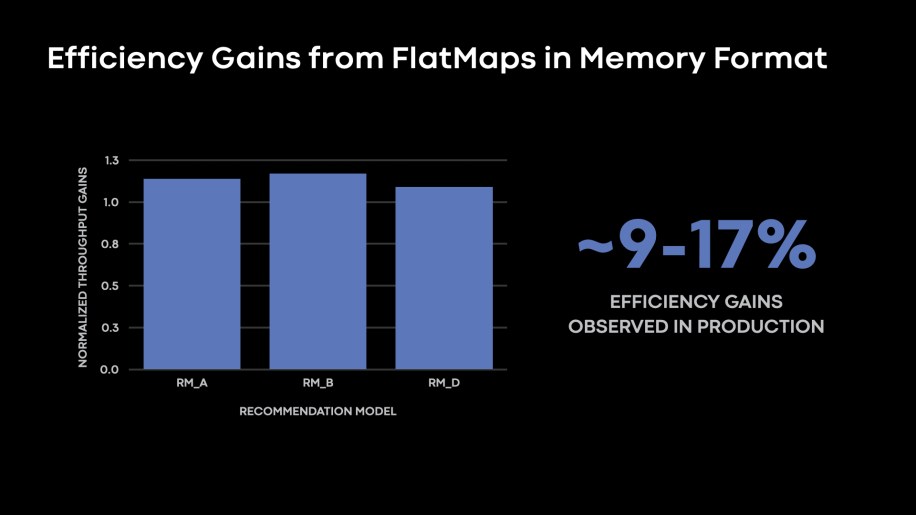
Fig. 10: 9-17 % the Rows/s throughput as executed by every reader node by making use of the FlatMaps in-memory knowledge representations.
Normally, optimizing knowledge studying tier reminiscence bandwidth utilization stays one of the compelling areas we proceed to spend money on to effectively make the most of the newer CPU variations touchdown in our knowledge facilities.
Scaling the storage tier to serve AI entry patterns
Allow us to check out what drives storage tier energy price. Regardless of particular person fashions coaching on terabyte- to petabyte-scale knowledge, we discover that lots of our fashions coaching on accelerators are IO certain attributable to huge coaching throughput demand. One motive for that is that fashions practice on a subset of options which might be saved in our dataset. Selectively looking for options consumed by fashions ends in smaller IOSize for our disk accesses, thus rising IOPs demand. Then again, if we overread consecutive options within the storage block to reduce seeks, we find yourself studying bytes that ultimately get dropped by coaching. That is illustrated in Fig. 11, beneath.
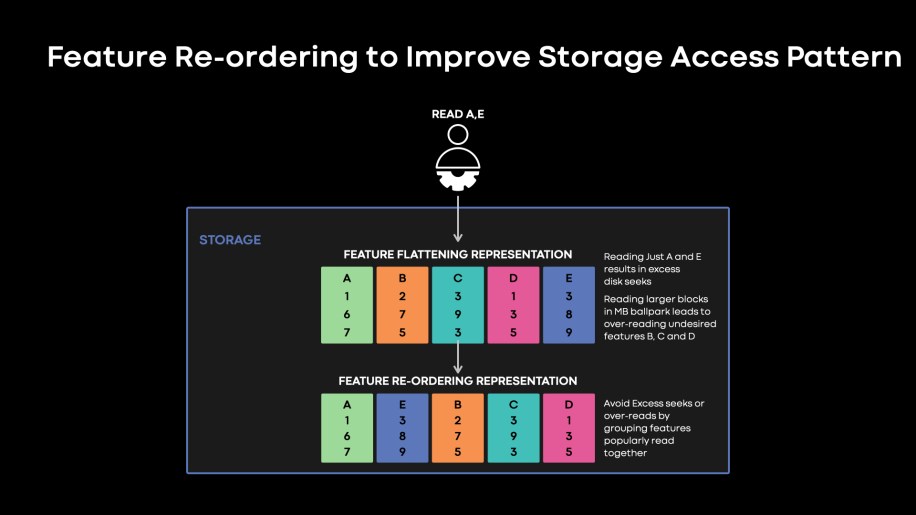
Fig. 11: Characteristic Re-ordering illustration. Characteristic re-ordering writes options which might be popularly consumed collectively in steady blocks in our storage tier.
Actually, we had some manufacturing fashions that had been NIC-bound on the reader ingress attributable to excessive overreads from the storage tier. By eliminating over-reads, we had been capable of additional enhance knowledge studying algorithmic effectivity for these fashions as we noticed these fashions transferring from being NIC-bound on the readers to reminiscence bandwidth-bound. Within the determine beneath, we current the discount we noticed in storage tier to reader tier knowledge switch and enchancment in storage tier service time as soon as we utilized function reordering.
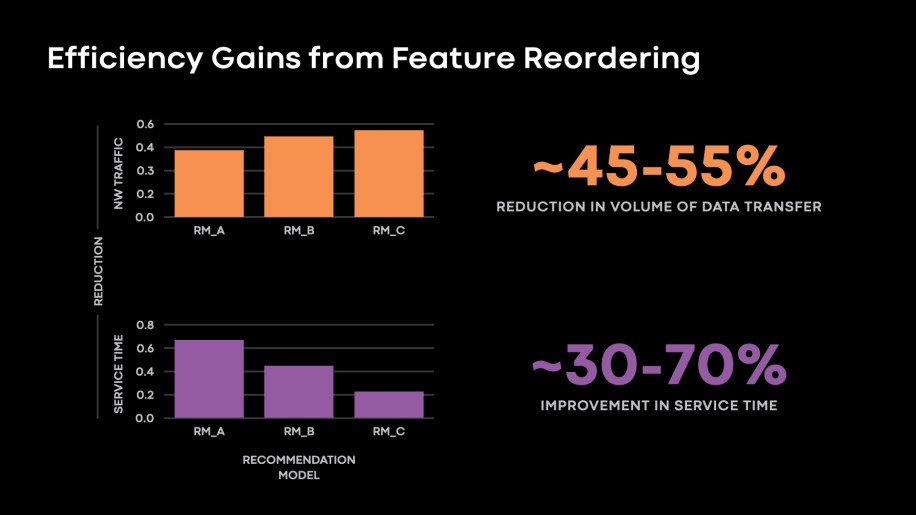
Fig. 12: Characteristic Re-ordering yielded 45-55% discount in quantity of knowledge transferred between storage tier and reader tiers. We additionally noticed 30-70% enchancment in service time for a number of of our fashions.
Making use of the optimizations mentioned on this put up, Fig. 13, beneath, illustrates the enhancements in knowledge ingestion energy funds noticed in our suggestion fashions.
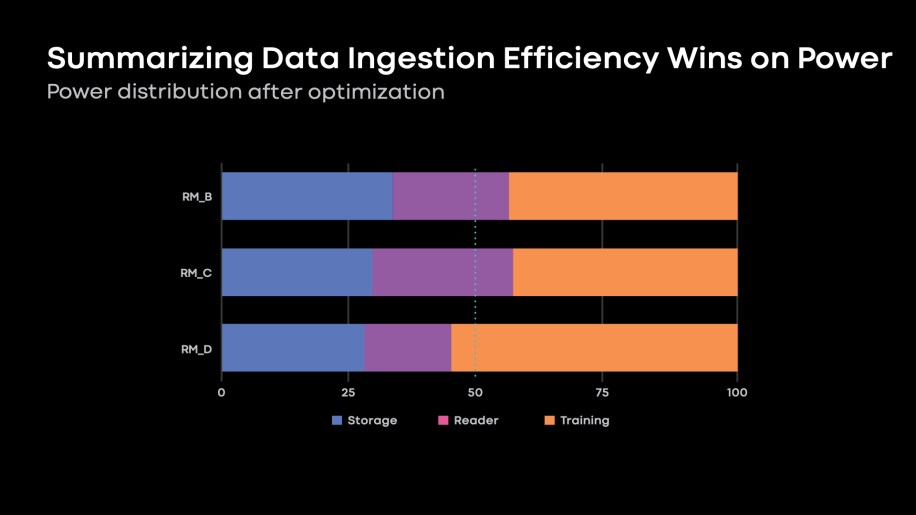
Fig. 13: 35-45 % enhancements in knowledge ingestion energy funds as in comparison with Fig. 4.
Areas of future exploration
We’re frequently working to optimize the pipelines answerable for last- mile knowledge ingestion and computation to satisfy the calls for of AI-driven merchandise at Meta. We’re dedicated to delivering an environment friendly and scalable infrastructure to assist our product groups in attaining this mission.
Listed below are just a few areas of exploration we’re inspecting going ahead:
Tiered storage: Lots of our datasets are massive sufficient that our fashions solely must do a single go. Therefore, we’re unable to take advantage of any knowledge reuse inside a job. Nevertheless, we are able to exploit reuse patterns throughout concurrent jobs utilizing the identical knowledge. We’re working towards constructing a tiered storage answer, HDD + SSD, with SSD serving because the caching tier for high-reuse options.
Preprocessing transformations on GPUs: There have been industry-wide efforts to execute preprocessing transformation operations on accelerators. We contiue our efforts to spend money on shifting the computation cycles of preprocessing from our hardware-constrained CPU to the beefier coaching accelerators. Outlining some challenges in our workloads on this area is that lots of our preprocessing operators truncate or clip the quantity of knowledge being despatched to coaching. With the potential of preprocessing transferring to coaching accelerators, we see the chance of elevated knowledge switch to push knowledge to the coaching accelerators. One other threat is that our fashions practice on numerous options and sometimes undergo a number of transformations earlier than the ultimate function is derived. This ends in non negligible CUDA kernel launch overheads, limiting the good points we are able to derive on this route. That stated, shifting preprocessing transformation to beefier coaching {hardware} is a really compelling route, and our groups are actively working to de-risk this area.
Storing derived options: Since our suggestion fashions typically practice with solely a single go over the info, this limits our potential to reuse knowledge inside a job. Nevertheless, we nonetheless discover potential of costly last-mile function transformations being reused throughout a number of impartial jobs. Our groups are engaged on figuring out frequent and costly transformations throughout impartial jobs. In doing so, we goal to advertise the transformations to full-fledged precomputed options in our storage tier as an alternative of evaluating them within the final mile of knowledge ingestion.
[ad_2]
Source_link





