14 Frequent Robots.txt Points (and The right way to Keep away from Them)

[ad_1]
Robots.txt recordsdata assist restrict search engine crawler (like Googlebot) from seeing unimportant pages in your website.
At seoClarity, we advocate Google’s tips and finest practices: configuring your website to manage how non-HTML content material is proven in search engine outcomes (or to ensure it isn’t proven) globally with X-Robots-Tag HTTP headers.
By blocking recordsdata by way of HTTP headers, you make sure that your website does not begin to see elevated indexation of URLs you do not need to seem in search outcomes.
This helps to keep away from potential safety points and any potential conflicts that may outcome from pages being listed that do not have to be. Robots.txt may also be an efficient means, however there are some potential points to pay attention to.
This is what we’ll cowl on this put up:
What’s a Robots.txt File?
Robots.txt recordsdata inform search engine crawlers which pages or recordsdata the crawler can or can’t request out of your website. In addition they block consumer brokers like bots, spiders, and different crawlers from accessing your website’s pages.
Under is an instance of what a robots.txt file appears like.
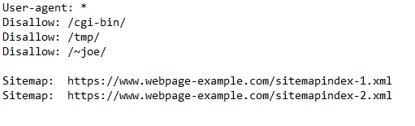 (A robots.txt with the required consumer agent, disallow, and sitemap standards.)
(A robots.txt with the required consumer agent, disallow, and sitemap standards.)
A search engine bot like Googlebot will learn the robots.txt file previous to crawling your website to study what pages it ought to cope with.
This may be useful if you wish to preserve a portion of your website out of a search engine index or if you need sure content material to be listed in Google however not Bing.
Instance of a Robots.txt File
Under is an instance from Google wherein Googlebot has blocked entry to sure directories whereas permitting entry to /directory2/subdirectory1/. You will additionally see that “anothercrawler” is blocked from all the website.
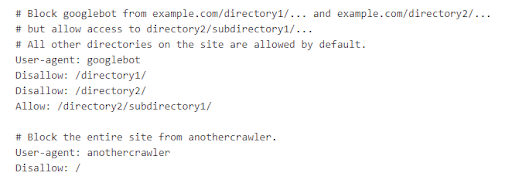
Consumer-agents are listed in “teams.” Every group may be designated inside its personal traces by crawler sort indicating which recordsdata it could actually and can’t entry.
Amassing bot exercise information is very necessary for figuring out any further bots, spiders, or crawlers that ought to be blocked from accessing your website’s content material.
Why are Robots.txt Information Essential?
Telling a crawler which pages to crawl and which pages to skip offers you better management over your website’s crawl finances, permitting you to direct crawlers to your most necessary property.
It is also necessary to notice that when consumer brokers like bots, spiders, and different crawlers hit your website, they’ll make the most of intensive assets (reminiscence and CPU) and may result in excessive load on the server that slows down your website.
By having a robots.txt file in place, you keep away from the potential of overloading your website’s servers with requests.
That is largely as a result of you possibly can handle the rise of visitors by crawlers and keep away from crawling unimportant or comparable pages in your website.
Belongings or recordsdata that Google doesn’t must waste crawl assets on can embrace:
-
- System URLs
- Login/account URLs
- Cart URLs
- Doubtlessly some aspects, filters, or type orders
Within the pattern robots.txt file under, there are coding property saved within the /cgi-bin folder on the web site. So including a disallow line permits crawlers to notice there are not any property inside this folder the location would need listed.
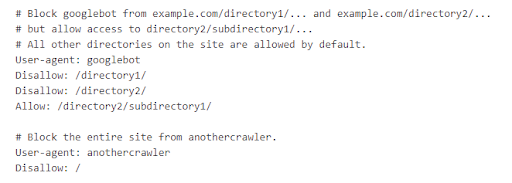
One caveat is that, in accordance with Google, pages which are blocked by way of robots.txt file should seem in search outcomes, however the search outcome is not going to have an outline and look one thing like this picture right here.
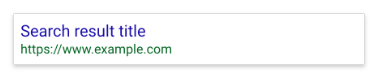
In case you see this search outcome on your web page and need to repair it, take away the road inside the robots.txt entry blocking the web page. Pages that also have backlinks pointing to the web page from different locations on the internet could doubtlessly nonetheless seem in search outcomes.
To correctly stop your URL from showing in Google Search outcomes, you must password shield the recordsdata in your server or use the noindex meta tag or response header (or take away the web page totally by way of 410 or different means).
You may also designate inside the robots.txt file which property you need to stop from showing in search outcomes together with particular photos, video, and audio recordsdata, in addition to block unimportant picture, script, or model recordsdata (for those who suppose that pages loaded with out these assets is not going to be considerably affected by the loss).
Really helpful Studying: Technical website positioning: Greatest Practices to Prioritize Your website positioning Duties
The Significance of Reviewing the Implementation of Robots.txt Information
As a result of robots.txt recordsdata point out to crawlers which pages and assets not to crawl (and subsequently people who will not be listed) they need to be reviewed to make sure the implementation is appropriate.
If pages or a bit of your website are disallowed from crawling via the robots.txt file, then any details about indexing or serving directives is not going to be discovered and can subsequently be ignored.
For instance, Googlebot is not going to see:
- Different meta-data content material
- Noindex tags
- Cannonical tags
- 404, 301, or 302 standing codes
Essential assets wanted to render web page content material (together with property wanted to load to extend web page pace, for instance) have to be crawled.
If indexing or serving directives should be adopted, the URLs containing these directives can’t be disallowed from crawling.
Usually, you shouldn’t block something that stops Google from rendering the pages the identical method a consumer would see the web page (i.e. photos, JS, CSS).
14 of the Most Frequent Robots.txt Points
One of the best ways to search out robots.txt errors is with a website audit. This allows you to uncover technical website positioning points at scale so you possibly can resolve them.
Listed here are frequent points with robots.txt particularly:
#1. Lacking Robots.txt
A web site with out a robots.txt file, robots meta tags, or X-Robots-Tag HTTP headers will typically be crawled and listed usually.
How this could grow to be a difficulty:
Having a robots.txt file is a beneficial finest observe for websites so as to add a stage of management to the content material and recordsdata that Google can crawl and index. Not having one merely signifies that Google will crawl and index all content material.
#2. Including Disallow Strains to Block Non-public Content material
Including a disallow line in your robots.txt file will even current a safety threat because it identifies the place your inner and personal content material is saved.
How this could grow to be a difficulty:
Use server-side authentication to dam entry to personal content material. That is particularly necessary for private identifiable data (PII).
#3. Including Disallow to Keep away from Duplicate Content material/Used As Against Canonicals
Websites have to be crawled with a purpose to see the canonical and roughly index. Don’t block content material by way of a robots.txt file in an try and deal with as canonicals.
How this could grow to be a difficulty:
Sure CMS and Dev environments could make it troublesome so as to add customized canonicals. On this occasion, Dev could strive different strategies as workarounds.
#4. Including Disallow to Code That’s Hosted on a Third-Celebration Website
If you wish to take away content material from a third-party website, you want to contact the webmaster to have them take away the content material.
How this could grow to be a difficulty:
This may happen in error when it is troublesome to interpret the supply server for particular content material.
#5. Use of Absolute URLs
The directives within the robots.txt file (except for “Sitemap:”) are solely legitimate for relative paths.
How this could grow to be a difficulty:
Websites with a number of sub-directories could need to use absolute URLs, however solely relative URLs are handed.
#6. Robots.txt Not Positioned in Root Folder
The file should be positioned within the top-most listing of the web site – not a sub-directory.
How this could grow to be a difficulty:
Guarantee that you’re not inserting the robots.txt in some other folder or sub-directories.
#7. Serving Totally different Robots.txt Information (Internationally or In any other case)
It’s not beneficial to serve completely different robots.txt recordsdata primarily based on the user-agent or different attributes.
How this could grow to be an issue:
Websites ought to all the time implement the identical robots.txt for worldwide websites.
#8. Added Directive to Block All Website Content material
Website house owners typically in growth sprints unintentionally set off the default robots.txt file which might then listing a disallow line that blocks all website content material.
How this could grow to be an issue:
This normally happens as an error or when a default is utilized throughout the location that impacts the robots.txt file and resets it to default.
#9. Including ALLOW vs. DISALLOW
Websites don’t want to incorporate an “enable” directive. The “enable” directive is used to override “disallow” directives in the identical robots.txt file.
How this could grow to be a difficulty:
In cases which the “disallow” may be very comparable, including an “enable” can help in including a number of attributes to assist distinguish them.
#10. Flawed File Kind Extension
Google Search Console Assist space has a put up that covers tips on how to create robots.txt recordsdata. After you’ve created the file, you possibly can validate it utilizing the robots.txt tester.
How this could grow to be a difficulty:
The file should finish in .txt and be created in UTF-8 format.
#11. Including Disallow to a Prime-Degree Folder The place Pages That You Do Need Listed Additionally Seem
Blocking Google from crawling a web page is more likely to take away the web page from Google’s index.
Within the instance under, an organization thought they had been limiting their crawl finances to not be wasted on filters and aspects. However, in actuality, they had been stopping the crawling of some main classes.
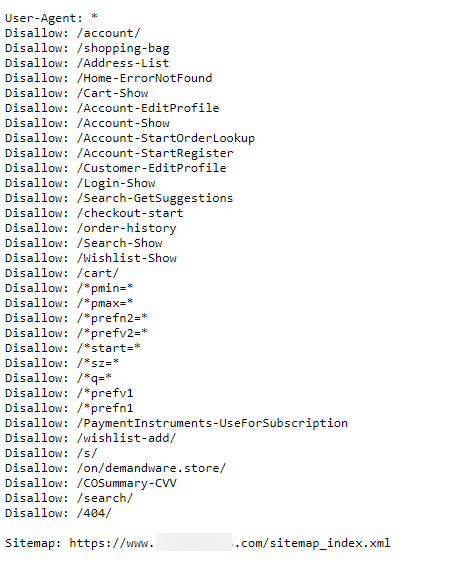
How this could grow to be a difficulty:
This normally happens as a result of placement of the asterix (*). When added earlier than a folder it could actually imply something in-between. When it’s added after, that’s an indication to dam something included within the URL after the /.
As you possibly can see on this website crawl, a big quantity of their website was being blocked by Robots.txt.
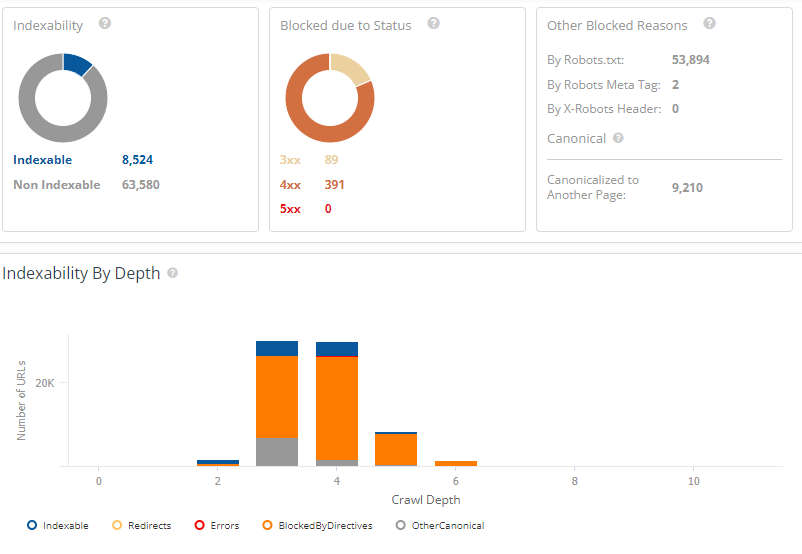
#12. Blocking Whole Website Entry Throughout Improvement
You possibly can briefly droop all crawling by returning an HTTP outcome code of 503 for all URLs, together with the robots.txt file. The robots.txt file shall be retried periodically till it may be accessed once more.
(We don’t advocate altering your robots.txt file to disallow crawling.)
How this could grow to be a difficulty:
When relocating a website or making huge updates, the robots.txt could possibly be empty default to blocking all the website. Greatest observe right here is to make sure that it stays on website and isn’t taken down throughout upkeep.
#13. Utilizing Capitalized Directives vs. Non-Capitalized
Remember that directives within the robots.txt file are case-sensitive.
How this could grow to be a difficulty:
Some CMS/Dev environments could routinely set URLs to render the robots.txt in uppercase and lowercase. The directives MUST match the precise 200-live standing URL construction.
#14. Utilizing Server Standing Codes (e.g. 403) to Block Entry
With a view to block crawling of the web site, the robots.txt should be returned usually (i.e. with a 200 “OK” HTTP outcome code) with an acceptable “disallow” in it.
How this could grow to be a difficulty:
When relocating a website or making huge updates, the robots.txt could possibly be empty or eliminated. Greatest observe is to make sure that it stays on website and isn’t taken down throughout upkeep.
The right way to Verify if Your Website Has X-Robots-Tag Carried out
A fast and straightforward option to verify the server headers is to make use of a web-based server header checker, or use the “Fetch as Googlebot” function in Search Console.
Google’s Greatest Practices for Utilizing Robots.txt Information
Now that you understand about among the most typical Robots.txt points, let’s go over Google’s finest practices for utilizing these recordsdata.
#1. Block Particular Net Pages
Robots.txt can be utilized to dam internet crawlers from accessing particular internet pages in your website, however make sure to comply with the seoClarity suggestion under.
seoClarity Tip
If there are particular pages you need to block from crawling or indexing, we advocate including a “no index” directive on the web page stage.
We advocate including this directive globally with X-Robots-Tag HTTP headers as the best resolution, and for those who want particular pages then add the “noindex” on the web page stage. Google affords a number of strategies on how to do that.
#2. Media Information
Use robots.txt to handle crawl visitors, and in addition stop picture, video, and audio recordsdata from showing within the SERP. Do word that this received’t stop different pages or customers from linking to your picture, video, or audio file.
If different pages or websites hyperlink to this content material, it might nonetheless seem in search outcomes.
seoClarity Tip
If the top aim is to have these media sorts not seem within the SERP, then you possibly can add it by way of the robots.txt file.
#3. Useful resource Information
You should use robots.txt to dam useful resource recordsdata, equivalent to unimportant picture, script, or model recordsdata for those who suppose that pages loaded with out these assets is not going to be considerably affected by the loss.
Nonetheless, if the absence of those assets make the web page more durable for Googlebot to grasp the web page, you shouldn’t block them, or else Google will be unable to investigate the pages that rely on these assets.
seoClarity Tip
We advocate this methodology if no different methodology works finest. In case you are blocking necessary assets (e.g. CSS script that renders the textual content on the web page) this might trigger Google to not render that textual content as content material.
Equally, if third-party assets are wanted to render the web page and are blocked, this might show to be problematic.
The right way to Deal with “Noindex” Attributes
Google doesn’t advocate including traces to your robots.txt file with the “noindex” directive. This line shall be ignored inside the robots.txt file.
In case you nonetheless have the “noindex” directive inside your robots.txt recordsdata, we advocate one of many following options:
#1. Use the Robots Meta Tag: <meta title=“robots” content material=”noindex” />
The above instance instructs engines like google to not present the web page in search outcomes. The worth of the title attribute (robots) specifies that the directive applies to all crawlers.
To deal with a selected crawler, exchange the “robots” worth of the title attribute with the title of the crawler that you’re addressing.
seoClarity Tip
That is beneficial for particular pages. The meta tag should seem within the <head> part. If there are particular pages that you simply need to block from crawling or indexing, we advocate including a “no index” directive on the web page. Google affords particular strategies to do that.
#2. Contact your Dev staff accountable for your server and configure the X-Robots-Tag HTTP Header
The X-Robots-Tag can be utilized as a component of the HTTP header response for a given URL. Any directive that can be utilized in a robots meta tag may also be specified as an X-Robots-Tag.
Right here is an instance of an HTTP response with a X-Robots-Tag instructing crawlers to not index a web page:
HTTP/1.1 200 OK
Date: Tue, 25 Might 2010 21:42:43 GMT
(…)
X-Robots-Tag: noindex
(…)
As well as, there could also be cases wherein you want to use a number of directives. In these cases, directives could also be mixed in a comma-separated listing.
seoClarity Tip
We advocate this as the popular methodology for any content material you need to be blocked from engines like google. World Directives on the folder stage are wanted.
The advantage of utilizing an X-Robots-Tag with HTTP responses is that you may specify crawling directives which are utilized globally throughout a website. That is dealt with in your server. To implement it, you want to attain out to your Dev Crew accountable for dealing with your website’s inner servers.
Key Takeaways
You need to evaluate our optimum implementation steps to make sure that your website follows all finest practices for robots.txt recordsdata and evaluate your website with the frequent errors that we’ve listed above.
Then, create a course of to deal with and take away noindex traces from robots.txt. Conduct a full website crawl to determine any further pages that ought to be added as disallow traces.
Make sure that your website is just not utilizing automated redirection or various the robots.txt. Benchmark your website’s efficiency previous to and after modifications.
Our Consumer Success Managers can help you in creating these stories to benchmark.
In case you want further help, our Skilled Providers staff is offered to assist diagnose any errors, offer you an implementation guidelines and additional suggestions, or help with QA testing.
<<Editor’s Observe: This piece was initially printed in April 2020 and has since been up to date.>>
[ad_2]
Source_link





