The Story of Blocking 2 Excessive-Rating Pages With Robots.txt

[ad_1]
I blocked two of our rating pages utilizing robots.txt. We misplaced a place right here or there and the entire featured snippets for the pages. I anticipated much more influence, however the world didn’t finish.
Warning
I don’t suggest doing this, and it’s fully doable that your outcomes could also be totally different from ours.
I used to be making an attempt to see the influence on rankings and site visitors that the elimination of content material would have. My principle was that if we blocked the pages from being crawled, Google must depend on the hyperlink indicators alone to rank the content material.
Nonetheless, I don’t assume what I noticed was truly the influence of eradicating the content material. Perhaps it’s, however I can’t say that with 100% certainty, because the influence feels too small. I’ll be working one other take a look at to verify this. My new plan is to delete the content material from the web page and see what occurs.
My working principle is that Google should still be utilizing the content material it used to see on the web page to rank it. Google Search Advocate John Mueller has confirmed this conduct within the previous.
To date, the take a look at has been working for almost 5 months. At this level, it doesn’t look like Google will cease rating the web page. I believe, after some time, it would possible cease trusting that the content material that was on the web page continues to be there, however I haven’t seen proof of that taking place.
Hold studying to see the take a look at setup and influence. The primary takeaway is that by accident blocking pages (that Google already ranks) from being crawled utilizing robots.txt in all probability isn’t going to have a lot influence in your rankings, and they’ll possible nonetheless present within the search outcomes.
I selected the identical pages as used within the “influence of hyperlink” research, apart from the article on website positioning pricing as a result of Joshua Hardwick had simply up to date it. I had seen the influence of eradicating the hyperlinks to those articles and needed to check the influence of eradicating the content material. As I mentioned within the intro, I’m undecided that’s truly what occurred.
I blocked these two pages on January 30, 2023:
These strains had been added to our robots.txt file:
Disallow: /weblog/top-bing-searches/Disallow: /weblog/top-youtube-searches/
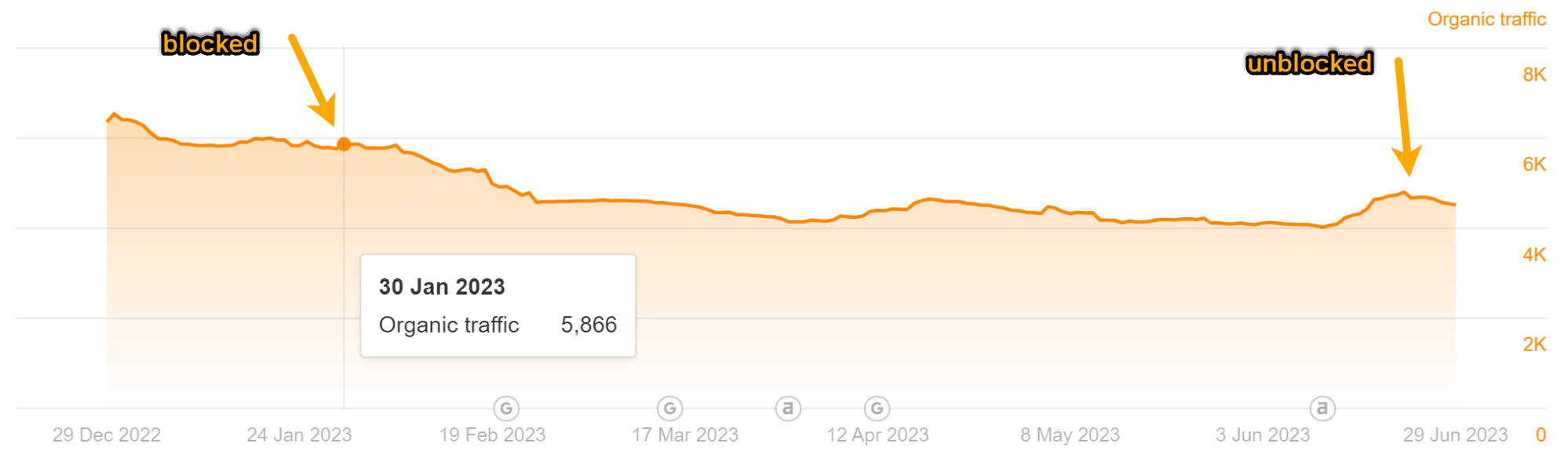
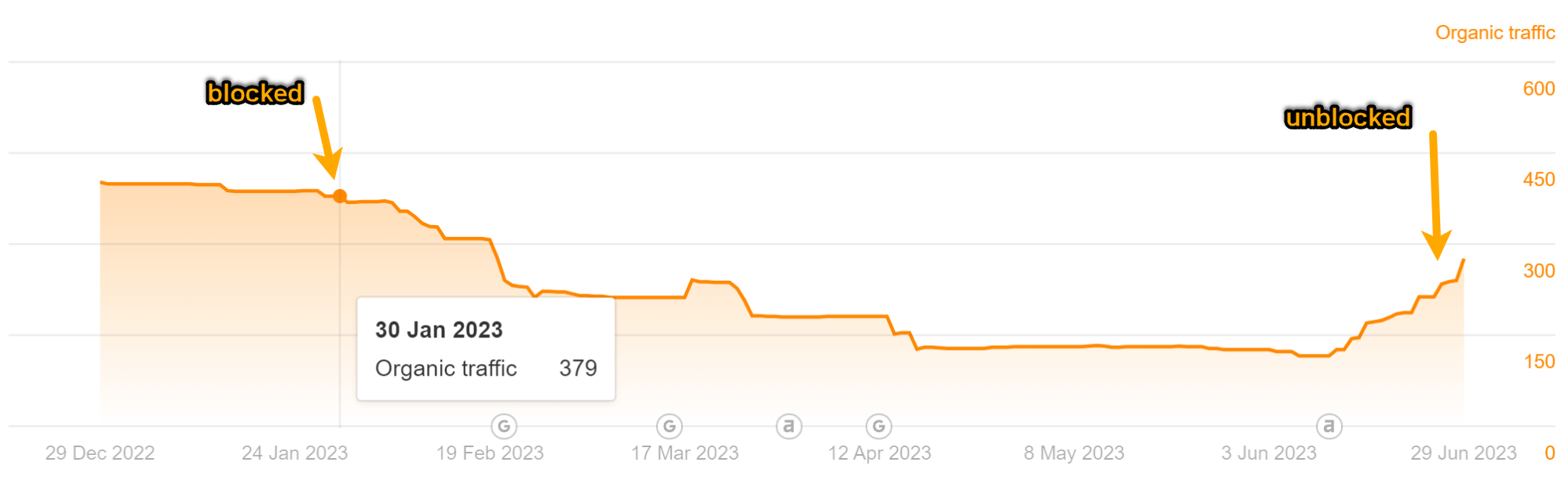
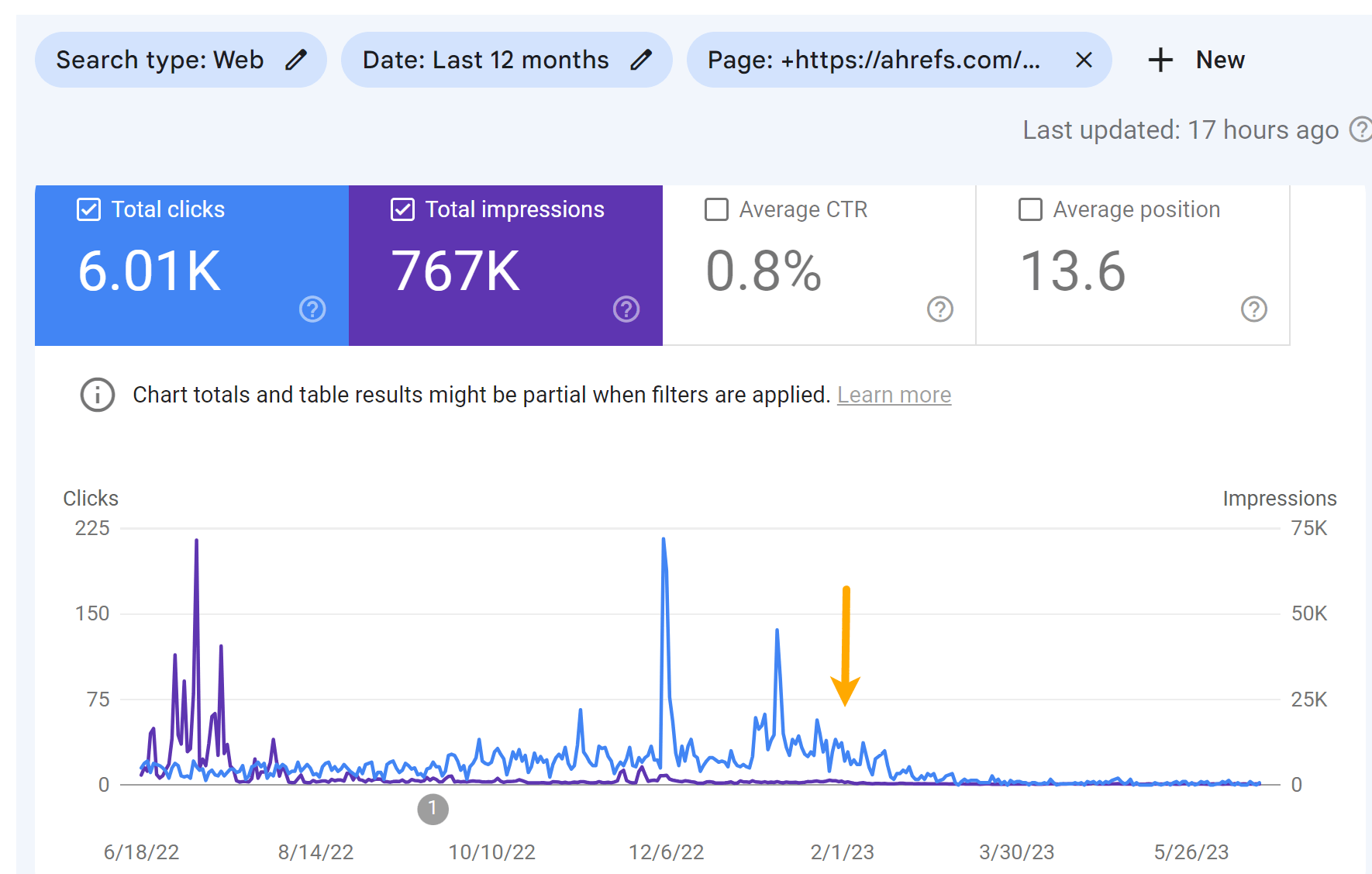
As you’ll be able to see within the charts under, each pages misplaced some site visitors. However it didn’t end in a lot change to our site visitors estimate like I used to be anticipating.
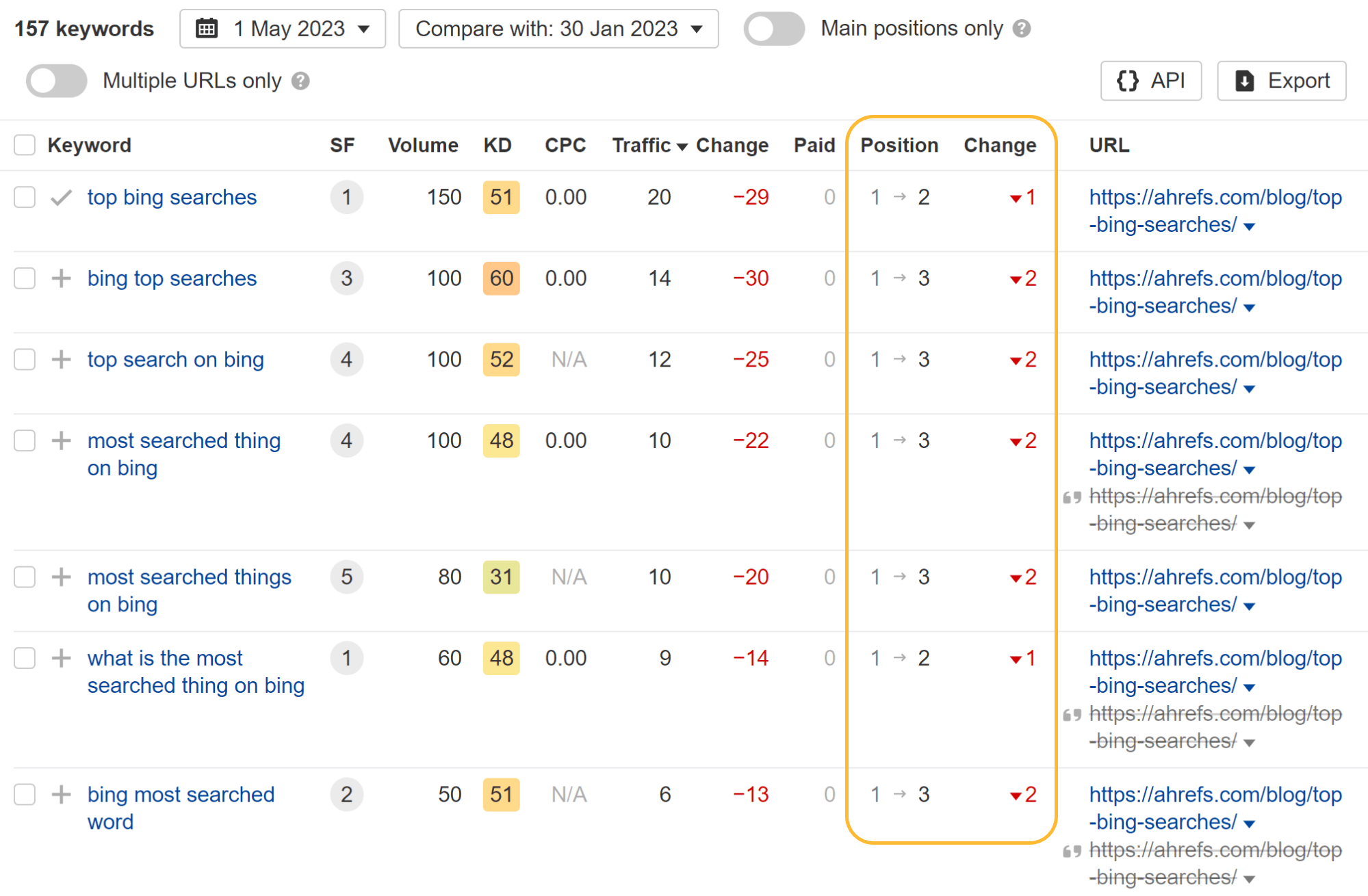
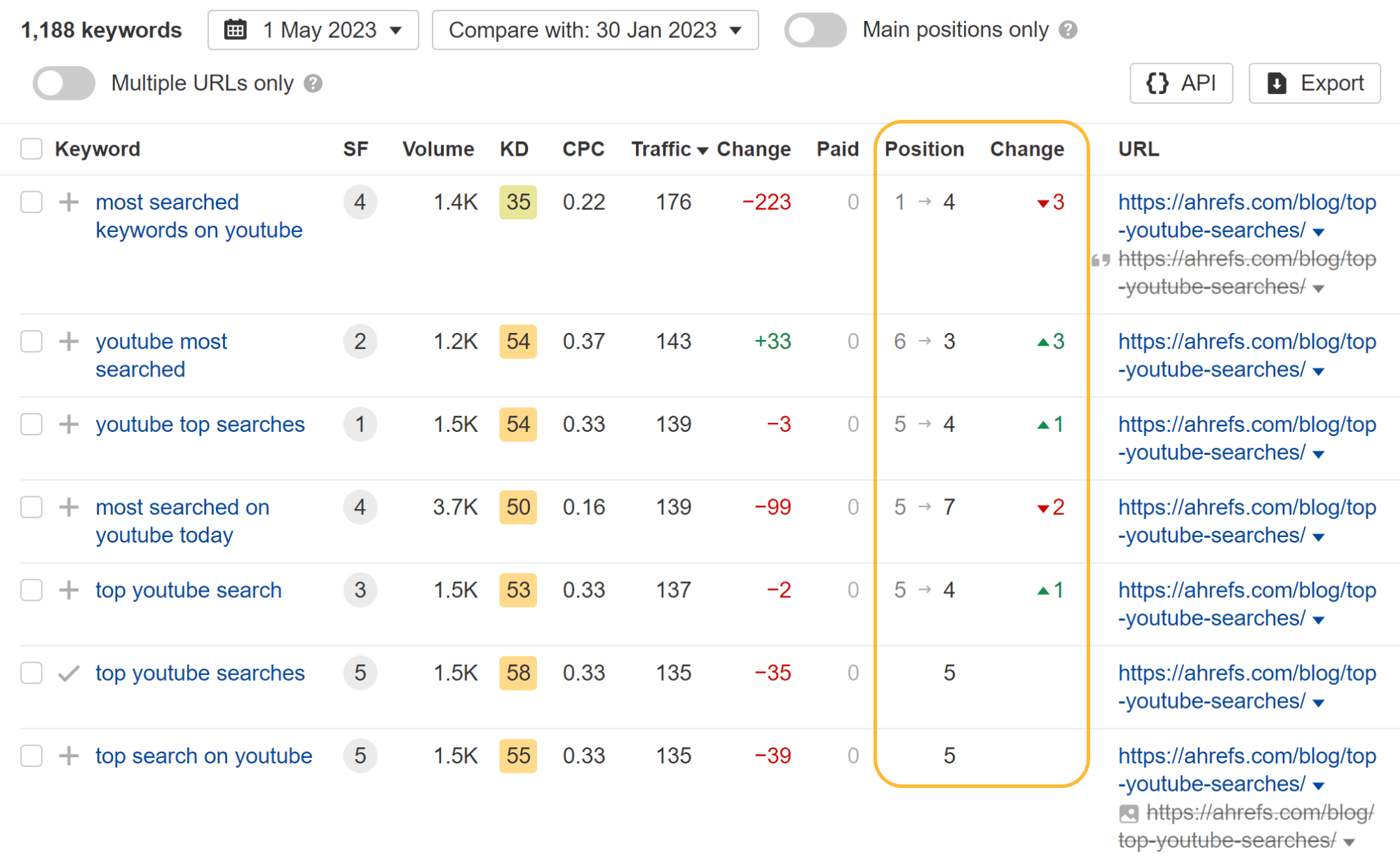
Trying on the particular person key phrases, you’ll be able to see that some key phrases misplaced a place or two and others truly gained rating positions whereas the web page was blocked from crawling.
Essentially the most fascinating factor I seen is that they misplaced all featured snippets. I assume that having the pages blocked from crawling made them ineligible for featured snippets. Once I later eliminated the block, the article on Bing searches rapidly regained some snippets.
Essentially the most noticeable influence to the pages is on the SERP. The pages misplaced their customized titles and displayed a message saying that no info was obtainable as a substitute of the meta description.
This was anticipated. It occurs when a web page is blocked by robots.txt. Moreover, you’ll see the “Listed, although blocked by robots.txt” standing in Google Search Console in case you examine the URL.
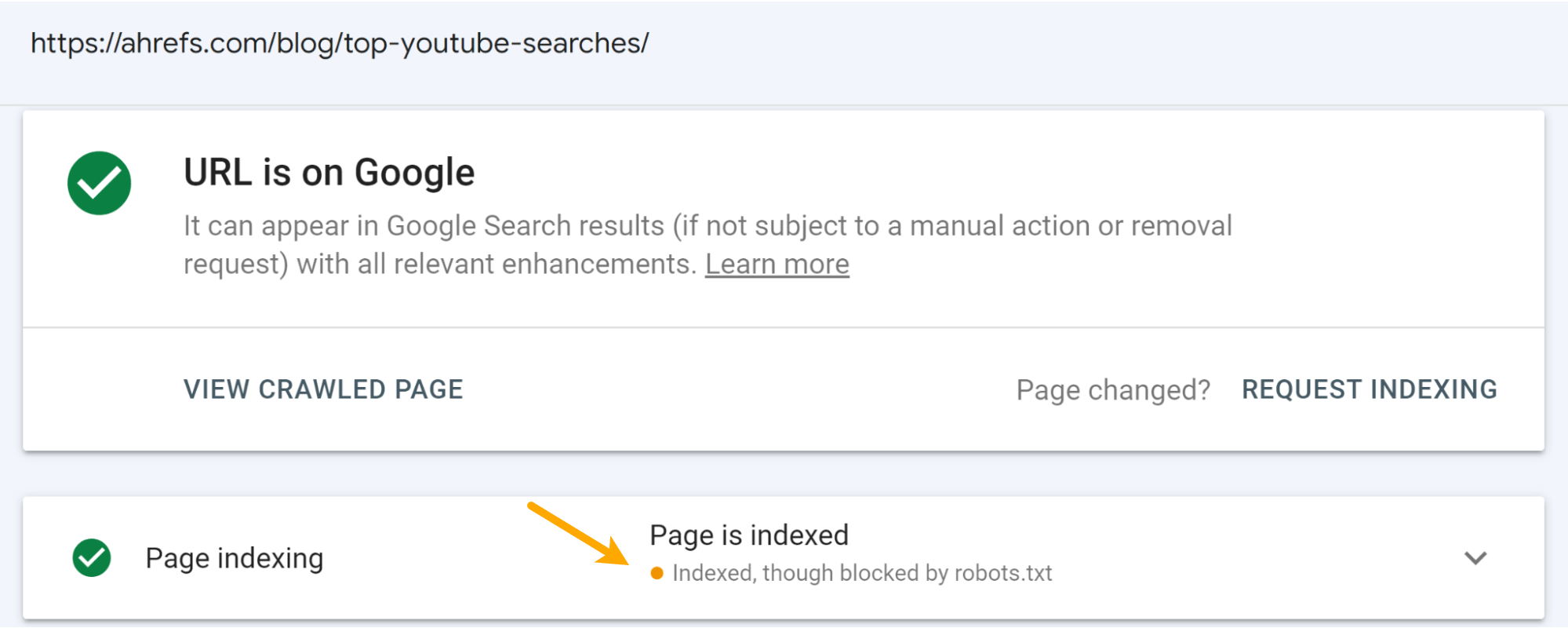
I imagine that the message on the SERPs damage the clicks to the pages greater than the rating drops. You possibly can see some drop within the impressions, however a bigger drop within the variety of clicks for the articles.
Visitors for the “High YouTube Searches” article:
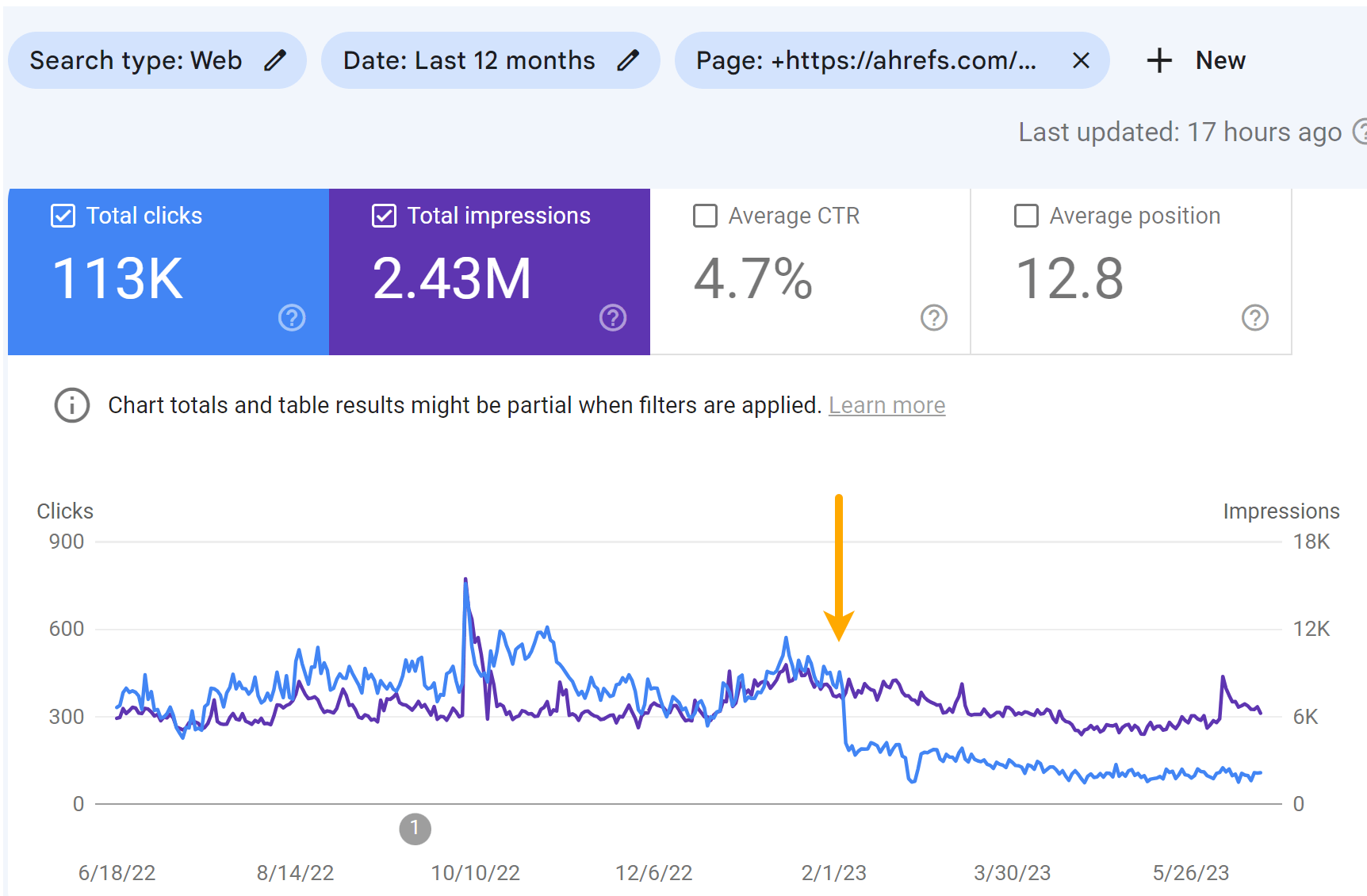
Visitors for the “High Bing Searches” article:
Closing ideas
I don’t assume any of you may be stunned by my commentary on this. Don’t block pages you need listed. It hurts. Not as unhealthy as you may assume it does—but it surely nonetheless hurts.
[ad_2]
Source_link





